1可见性原子性有序性问题之并发编程bug的源头
并发程序幕后
矛盾:CPU、内存、I/O设备的速度差异
为了合理利用CPU的高性能,平衡三者差异,计算机体系结构,操作系统,编译程序做出了贡献:
- CPU增加缓存,均衡与内存的速度差异
- 操作系统增加进程、线程,以分时复用CPU,均衡CPU与I/O设备的速度差异
- 编译程序优化指令执行次序,使得缓存能够被更合理利用
以上也是并发问题的根源所在。
源头一:缓存导致的可见性问题
一个线程对共享变量的修改,另外一个线程能够立刻看到,称为可见性
多核CPU,每个CPU有自己的缓存。并发执行i++,线程A在CPU1中执行,线程B在CPU2中执行,线程A对CPU2的缓存不具备可见性,就会导致并发问题。
并发执行1000次结果会小于2000。并发执行次数越高1亿次回趋近1亿而不是2亿,因为两个线程不是同时启动的,有一个时差。
源头二:线程切换带来的原子性问题
我们把一个或者多个操作在CPU执行的过程中不被中断的特性称为原子性。
CPU能保证的原子操作是CPU指令级别的,而不是高级语言的操作符,
高级语言里一条语句往往需要多条 CPU 指令完成,如:count += 1
需三条指令:
- 把变量 count 从内存加载到 CPU 的寄存器
- 在寄存器中执行 +1 操作
- 将结果写入内存(缓存机制导致可能写入的是 CPU 缓存而不是内存)
如下图,期望结果是1而不是2。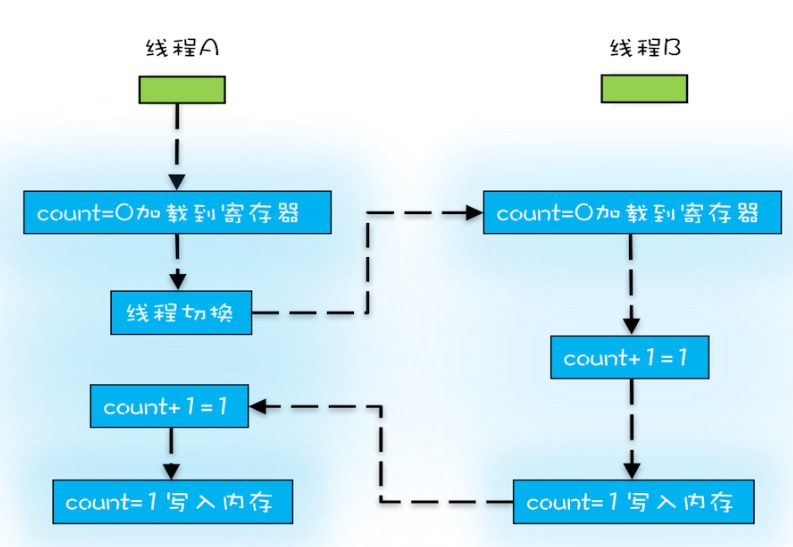
源头三:编译优化带来的有序性问题
DCL问题
1 | public class Singleton { |
new操作是问题所在,我们以为的new操作:
- 分配一块内存M;
- 在内存M上初始化Singleton对象;
- 然后M的地址赋值给instance变量。
指令优化后的却是: - 分配一块内存M;
- 将M的地址赋值给instance变量;
- 最后在内存M上初始化Singleton对象。
假设线程A先执行 getInstance() 方法,执行完指令2发生线程切换,切换到线程B;如果此时线程B也执行getInstance()方法,那么线程B在执行第一个判断时会发现instance != null,所以直接返回 instance,而此时的 instance 是没有初始化过的,如果我们这个时候访问instance 的成员变量就可能触发空指针异常。
总结
缓存带来了可见性问题,线程切换带来了原子性问题,编译优化带来了有序性问题。三者提高程序性能,解决一个问题的同时带来另外问题,所以采用一项技术的同时,要清楚它带来的问题是什么,以及如何规避。
volatile :禁止指令重排,禁用缓存保证可见性。
实现原理:内存屏障
四种屏障类型:LoadLoad,StoreStore,LoadStore,StoreLoad。
重排规则:
- 第二个操作是volatile写时,不管第一个操作是什么,都不能重排序。这个规则确保volatile写之前的操作不会被编译器重排序到volatile写之后。
- 第一个操作是volatile读时,不管第二个操作是什么,都不能重排序。这个规则确保volatile读之后的操作不会被编译器重排序到volatile读之前。
- 当第一个操作是volatile写,第二个操作是volatile读时,不能重排序。
问题
- 在 32 位的机器上对 long 型变量进行加减操作存在并发隐患,到底是不是这样呢?
long是64位,32位操作系统字长是32位,一次加减操作分成了高32位和低32位操作,两个cpu指令操作不能保证原子性