2构建底层索引和搜索机制
学习目标
- 理解搜索底层的执行过程和原理
- 掌握lucene构建索引和执行搜索的实现方法
目录
- lucene构建索引
- lucene执行搜索
- lucene分析过程
lucene构建索引
lucene核心
- 构建索引
- 文档分析
- 索引构建
- 索引搜索
- 建立搜索(构建搜索条件[模式pattern:单词/多次,结果评分规则])
- 执行搜索
索引构建过程
索引存放目录Directory
创建Document
初始化Field
初始化分析器 Analyzer
IndexWriter创建更新索引
segment
索引性能差如何优化?
setMergeFactor
segment中的文档数达到一定数量时合并
批处理文档索引时(如新建索引)设置较大值索引较快
间歇性追加文档索引时设置较小值,每次合并占用内存少
setMaxMergeDocs
segment最大合并文档(Document)数
值较小,建立索引的速度就较慢
值较大,建立索引的速度就较快,>10适合批量建立索引
lucene执行搜索
初始化分析器Analizer
确定要查询的域名fields_name
根据Analyzer fields_name 初始化QueryParser
QueryParser将搜索文本转换为Query对象
构建IndexSearcher(new IndexSearcher(DirectoryReader.open(FSDirectory))
IndexSearcher对象查询Query
lucene分析过程
创建索引、搜索索引时执行分析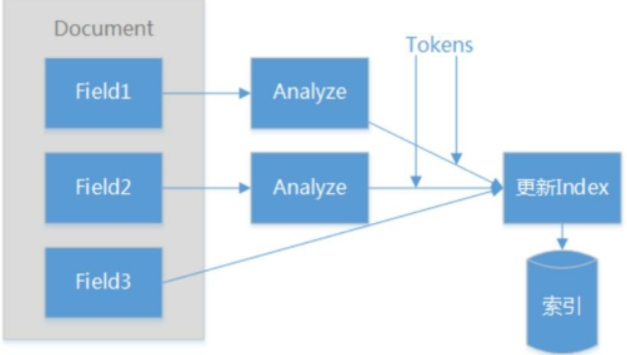
分析是将Field(域)文本转换为Term(项)的过程
分析生成的基本单元为Token。
不同领域文本有不同特性,不同分析器分析不同领域的文本。
Token
分词信息
结构:文本值+元数据(各种偏移量)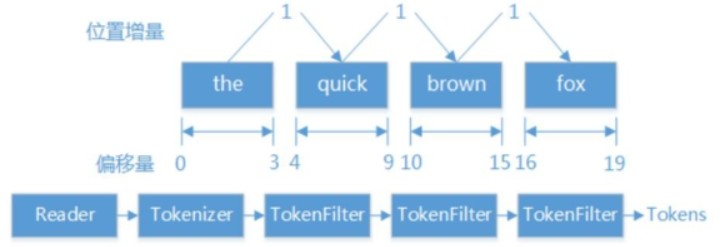
TermAttribute 词汇单元对应的文本
PositionincrementAttribute 位置增量
OffsetAttribute 起始字符和终止字符的偏移量
TypeAttribute 词汇单元类型
FlagsAttribute 自定义标志位
PayloadAttribute 词汇单元的有效负载
内置分析器
WhitespaceAnalyzer通过空格分隔文本
SimpleAnalyzer非字母分隔文本
StopAnalyzer去掉常用单词
StandardAnalyzer最复杂的核心分析器
“The quick brown fox jumped over the lazy dog”
WhitespaceAnalyzer:
[The][quick][brown][fox][jumped] [over][the][lazy][dog]
SimpleAnalyzer:
[the][quick][brown][fox][jumped][over][the] [lazy][dog]
StopAnalyzer:
[quick] [brown][fox][jumped][over] [lazy] [dog]
StandardAnalyzer:
[quick][brown][fox][jumped][over] [lazy][dog]
“xY&z Corporation -xyz@example.com‘
WhitespaceAnalyzer:
[xY&z][Corporation][-][xyz@example.com]
SimpleAnalyzer:
[xy][z][Corporation][xyz][example] [com]
StopAnalyzer:
[xy][z][corporation][xyz][example] [com]
StandardAnalyzer:
[xy&z][Corporation][xyz@example.com]
分析器的执行效果与词库相关
问题
文本内容如何转换为索引?