2java内存模型
Java如何解决可见性和有序性问题?
java内存模型
是一个复杂的规范。定义线程如何通过内存交互。主要包括两部分
- 站在程序员角度可理解为,java内存模型规范了按需禁用缓存和编译优化的方法,包括volatile,synchronized和final三个关键字,以及Happens-Before规则。
- 面相JVM的实现人员
final关键字:初衷是告诉编译器,此生而变量不变,可随意优化。
Happens-Before
前面一个操作的结果对后续操作是可见的,不是说执行先后顺序。
约束编译器的优化行为,允许编译器优化,但是要求优化后遵守Happens-Before规则
Happens-Before六项规则
程序的顺序性规则
同一个线程中,按照程序顺序,前面的操作Happens-Before于后续的任意操作。volatile 变量规则
volatile变量的写操作Happens-Before于后续对这个volatile变量的读操作。
volatile变量的写操作相对于后续对这个volatile变量的读操作可见,这怎么看都是禁用缓存的意思啊。关联规则3传递性
A Happens-Before B,且B Happens-Before C,那么A Happens-Before C。1
2
3
4
5
6
7
8
9
10
11
12
13class VolatileExample {
int x = 0;
volatile boolean v = false;
public void writer() {
x = 42;//1
v = true;//2
}
public void reader() {
if (v == true) {//3
// 这里 x 会是多少呢?//4
}
}
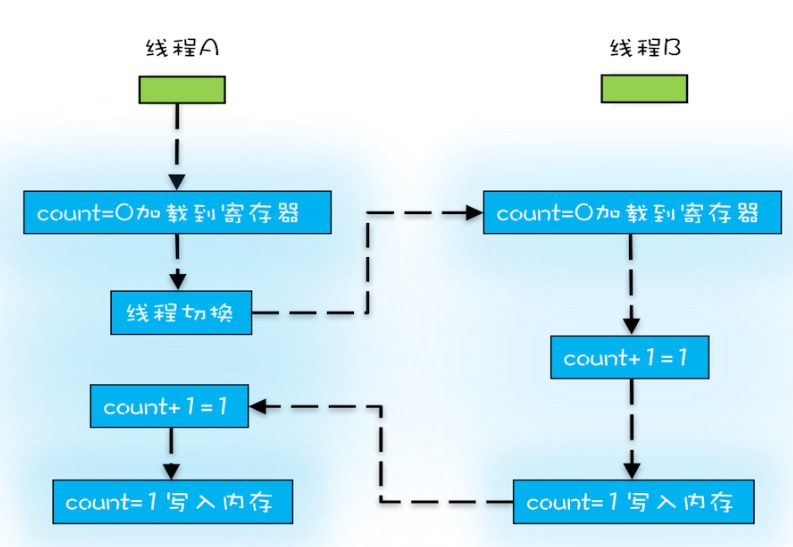
}1HappensBefore2,2HappensBefore3,则得到1HappensBefore4则输出是42
管程中锁的规则(sychronized锁规则)
管程是一种通用的同步原语,在 Java 中指的就是 synchronized,synchronized 是Java里对管程的实现。
此规则指:对一个锁的解锁Happens-Before于后续对这个锁的加锁线程start()规则
指主线程A启动子线程B后,子线程B能够看到主线程在启动子线程B前的操作。
1 | Thread B = new Thread(()->{ |
- 线程join()规则
指主线程A等待子线程B完成,当子线程B完成后主线程能够看到子线程对共享变量的操作。1
2
3
4
5
6
7
8
9
10
11
12Thread B = new Thread(()->{
// 此处对共享变量 var 修改
var = 66;
});
// 例如此处对共享变量修改,
// 则这个修改结果对线程 B 可见
// 主线程启动子线程
B.start();
B.join()
// 子线程所有对共享变量的修改
// 在主线程调用 B.join() 之后皆可见
// 此例中,var==66